2.2-神经网络的训练
本小节主要围绕神经网络的训练的训练流程,损失函数,梯度下降和反向传播展开。
2.2.1 基本训练流程
从真正的“零”开始学习神经网络时,我没有看到过任何一个流程图来讲述训练过程,大神们写书或者博客时都忽略了这一点,图 2.2.1 是一个简单的流程图。
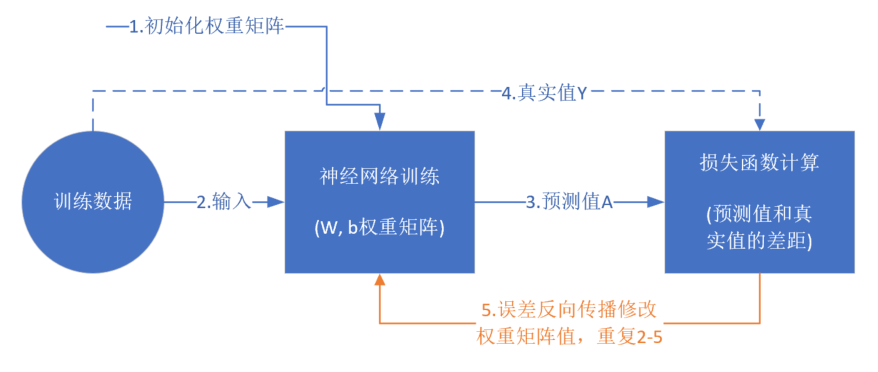
图 2.2.1 神经网络训练流程图
前提条件
- 首先是我们已经有了训练数据;
- 我们已经根据数据的规模、领域,建立了神经网络的基本结构,比如有几层,每一层有几个神经元;
- 定义好损失函数来合理地计算误差。
步骤
假设我们有表 2.2.1 所示的训练数据样本。
表 2.2.1 训练样本示例
| Id | ||||
|---|---|---|---|---|
| 1 | 0.5 | 1.4 | 2.7 | 3 |
| 2 | 0.4 | 1.3 | 2.5 | 5 |
| 3 | 0.1 | 1.5 | 2.3 | 9 |
| 4 | 0.5 | 1.7 | 2.9 | 1 |
其中, 是每一个样本数据的三个特征值, 是样本的真实结果值:
- 随机初始化权重矩阵,可以根据正态分布等来初始化。这一步可以叫做“猜”,但不是瞎猜;
- 拿一个或一批数据 作为输入,带入权重矩阵 中计算 ,再通过激活函数传入下一层 ,最终得到预测值。在本例中,我们先用 的数据输入到矩阵中,得到一个 值,假设 ;
- 拿到 样本的真实值 ;
- 计算损失,假设用均方差函数 ;
- 根据一些神奇的数学公式(反向微分),把 这个值用大喇叭喊话,告诉在前面计算的步骤中,影响 这个值的每一个权重矩阵 ,然后对这些权重矩阵中的值做一个微小的修改(当然是向着好的方向修改);
- 用 样本作为输入再次训练(Go to 2);
- 这样不断地迭代下去,直到以下一个或几个条件满足就停止训练:损失函数值非常小;准确度满足了要求;迭代到了指定的次数。
训练完成后,我们会把这个神经网络中的结构和权重矩阵的值导出来,形成一个计算图(就是矩阵运算加上激活函数)模型,然后嵌入到任何可以识别/调用这个模型的应用程序中,根据输入的值进行运算,输出预测值。
所以,神经网络的训练需要三个概念的支持,依次是:
- 损失函数
- 梯度下降
- 反向传播
2.2.2 损失函数
概念
在各种材料中经常看到的中英文词汇有:误差,偏差,Error,Cost,Loss,损失,代价......意思都差不多,在本书中,使用“损失函数”和“Loss Function”这两个词汇,具体的损失函数符号用 来表示,误差值用 表示。
“损失”就是所有样本的“误差”的总和,亦即( 为样本数):
损失 = \sum^m_{i=1}误差_i损失函数的作用
损失函数的作用,就是计算神经网络每次迭代的前向计算结果与真实值的差距,从而指导下一步的训练向正确的方向进行。
如果我们把神经网络的参数调整到完全满足独立样本的输出误差为 ,通常会令其它样本的误差变得更大,这样作为误差之和的损失函数值,就会变得更大。所以,我们通常会在根据某个样本的误差调整权重后,计算一下整体样本的损失函数值,来判定网络是不是已经训练到了可接受的状态。
损失函数有两个作用:
- 用损失函数计算预测值和标签值(真实值)的误差;
- 损失函数值达到一个满意的值就停止训练。
神经网络常用的损失函数有:
均方差函数,主要用于回归
交叉熵函数,主要用于分类
二者都是非负函数,极值在底部,用梯度下降法可以求解。
均方差函数
MSE - Mean Square Error。
该函数就是最直观的一个损失函数了,计算预测值和真实值之间的欧式距离。预测值和真实值越接近,两者的均方差就越小。
均方差函数常用于线性回归(linear regression),即函数拟合(function fitting)。公式如下:
loss = {1 \over 2}(z-y)^2 \tag{单样本} J=\frac{1}{2m} \sum_{i=1}^m (z_i-y_i)^2 \tag{多样本,m为样本个数}只有两个参数 的损失函数值的 3D 示意图如图 2.2.2。
X 坐标为 ,Y 坐标为 ,针对每一个 的组合计算出一个损失函数值,用三维图的高度 Z 来表示这个损失函数值。下图中的底部并非一个平面,而是一个有些下凹的曲面,只不过曲率较小。
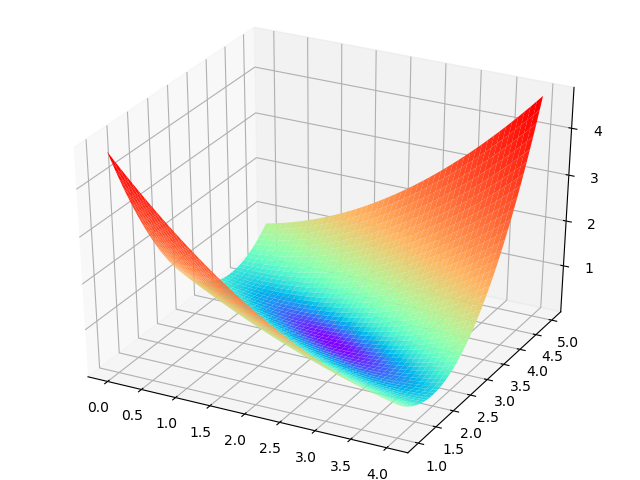
图 2.2.2 和 同时变化时的损失函数形态
交叉熵损失函数
单个样本的情况的交叉熵函数:
其中, 并不是样本个数,而是分类个数。
对于批量样本的交叉熵计算公式是:
是样本数, 是分类数。
有一类特殊问题,就是事件只有两种情况发生的可能,比如“学会了”和“没学会”,称为 分类或二分类。对于这类问题,由于,所以交叉熵可以简化为:
二分类对于批量样本的交叉熵计算公式是:
交叉熵函数常用于逻辑回归(logistic regression),也就是分类(classification)。
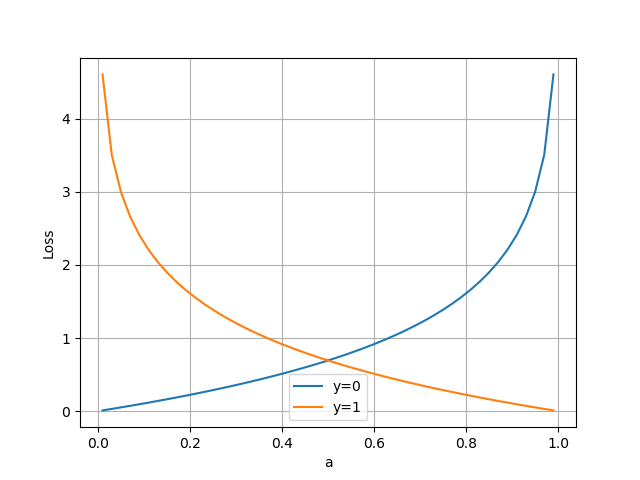
图 2.2.3 二分类交叉熵损失函数图
从图 2.2.3 可以看到:
当分类为正类时,即 的红色曲线,当预测值 也为 1 时,损失函数值最小为 0;随着预测值 变小,损失函数值会变大;
当分类为负类时,即 的蓝色曲线,当预测值 也为 0 时,损失函数值最小为 0;随着预测值 变大,损失函数值会变大;
2.2.3 梯度下降
从自然现象中理解梯度下降
在自然界中,梯度下降的最好例子,就是泉水下山的过程:
- 水受重力影响,会从当前位置沿着最陡峭的方向流动,有时会形成瀑布(梯度下降);
- 水流下山的路径不是唯一的,在同一个地点,有可能有多个位置具有同样的陡峭程度,而造成了分流(可以得到多个解);
- 遇到坑洼地区,有可能形成湖泊,而终止下山过程(不能得到全局最优解,而是局部最优解)。
梯度下降的数学理解
梯度下降的数学公式:
其中:
- :下一个参数值;
- :当前参数值;
- :减号,梯度的反向;
- :学习率或步长,控制每一步走的距离,不要太快以免错过了最佳景点,不要太慢以免时间太长;
- :梯度,函数当前位置的最快上升点;
- :函数。
对应到上面的例子中, 就是 的组合。
梯度下降的三要素
- 当前点;
- 方向;
- 步长。
为什么说是“梯度下降”?
“梯度下降”包含了两层含义:
- 梯度:函数当前位置的最快上升点;
- 下降:与导数相反的方向,用数学语言描述就是那个减号。
亦即与上升相反的方向运动,就是下降。
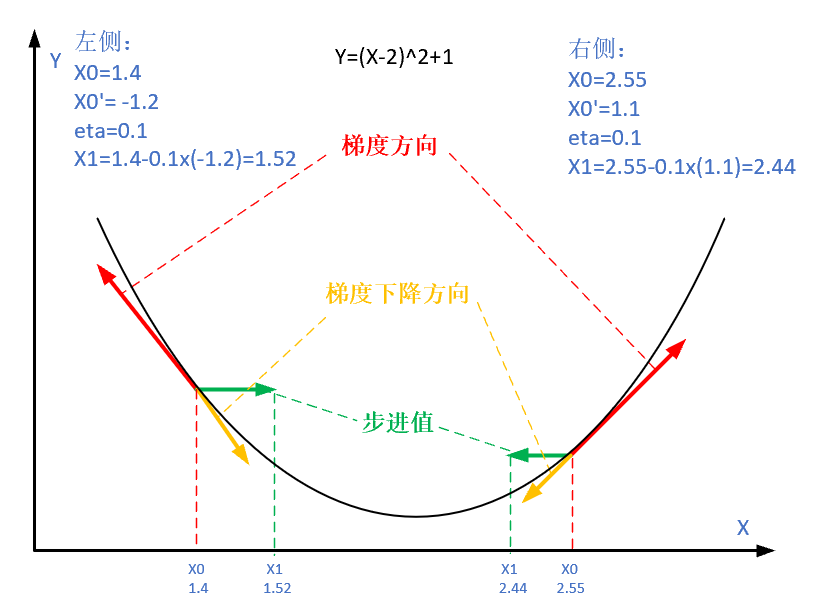
图 2.2.4 梯度下降的步骤
图 2.2.4 解释了在函数极值点的两侧做梯度下降的计算过程,梯度下降的目的就是使得x值向极值点逼近。
学习率η的选择
在公式表达时,学习率被表示为。在代码里,我们把学习率定义为learning_rate,或者eta。针对上面的例子,试验不同的学习率对迭代情况的影响,如表 2.2.2 所示。
表 2.2.2 不同学习率对迭代情况的影响
| 学习率 | 迭代路线图 | 说明 |
|---|---|---|
| 1.0 | 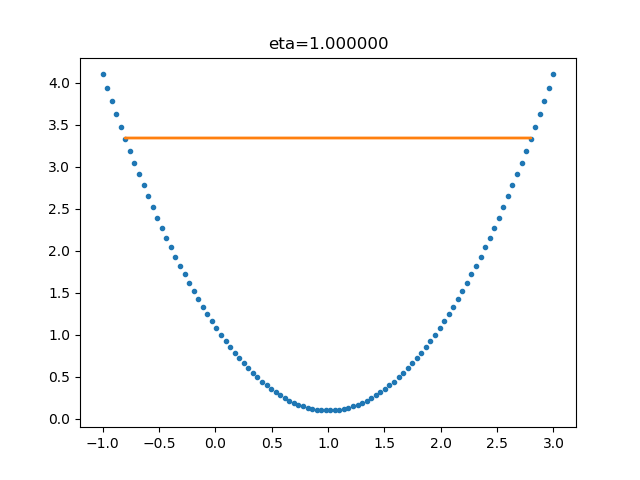 | 学习率太大,迭代的情况很糟糕,在一条水平线上跳来跳去,永远也不能下降。 |
| 0.8 | 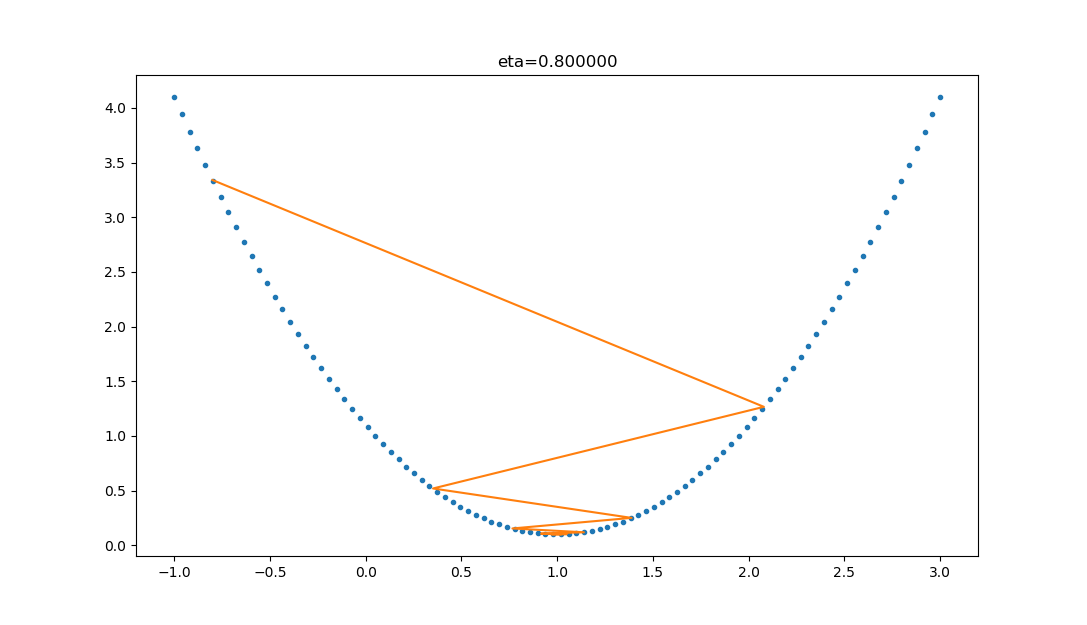 | 学习率大,会有这种左右跳跃的情况发生,这不利于神经网络的训练。 |
| 0.4 | 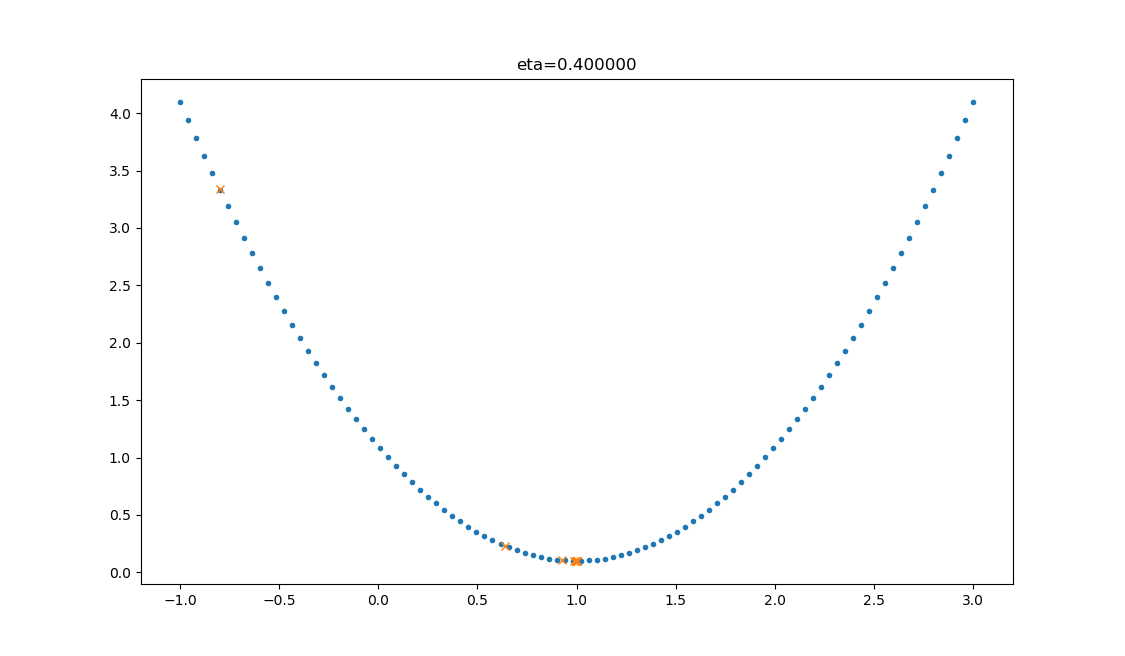 | 学习率合适,损失值会从单侧下降,4步以后基本接近了理想值。 |
| 0.1 | 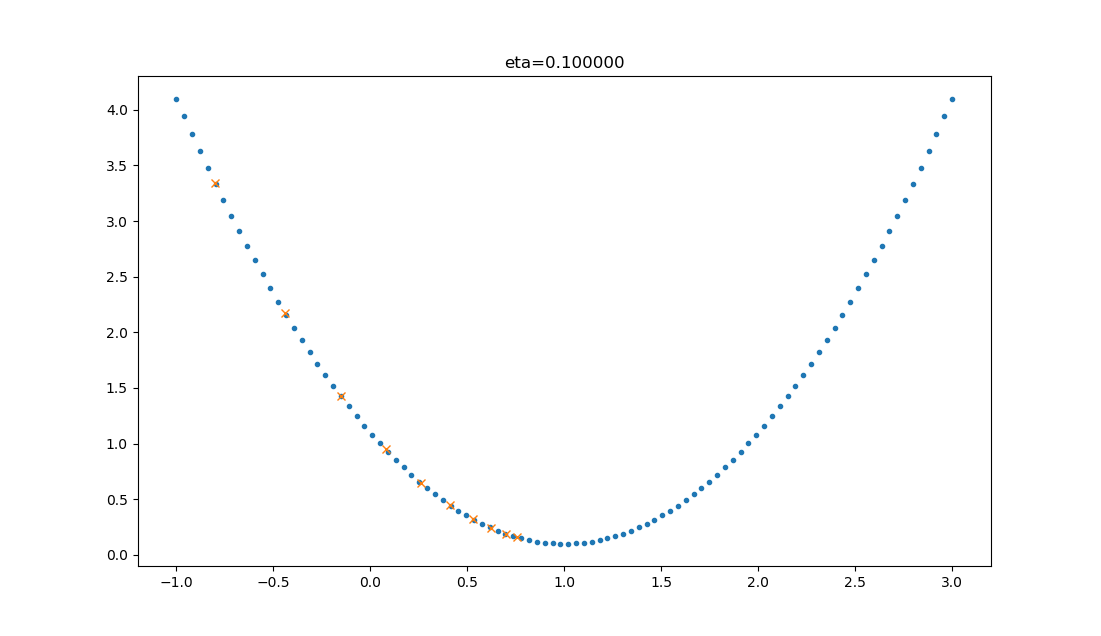 | 学习率较小,损失值会从单侧下降,但下降速度非常慢,10步了还没有到达理想状态。 |
2.2.4 反向传播
假设有一个黑盒子,输入和输出有一定的对应关系,我们要破解这个黑盒子!于是,我们会有如下破解流程:
- 记录下所有输入值和输出值,如表2.2.3。
表 2.2.3 样本数据表
| 样本ID | 输入(特征值) | 输出(标签) |
|---|---|---|
| 1 | 1 | 2.21 |
| 2 | 1.1 | 2.431 |
| 3 | 1.2 | 2.652 |
| 4 | 2 | 4.42 |
- 搭建一个神经网络,我们先假设这个黑盒子的逻辑是:;
- 给出初始权重值,;
- 输入1,根据 得到输出为2,而实际的输出值是2.21;
- 计算误差值为 ;
- 调整权重值,假设只变动 ,比如 ,令学习率 ,则
- 再输入下一个样本1.1,得到的输出为
- 实际输出为2.431,则误差值为 ;
- 再次调整权重值, ......
依此类推,重复 4-9 过程,直到损失函数值小于一个指标,比如 ,我们就可以认为网络训练完毕,黑盒子“破解”了,实际是被复制了,因为神经网络并不能得到黑盒子里的真实函数体,而只是近似模拟。
从上面的过程可以看出,如果误差值是正数,我们就把权重降低一些;如果误差值为负数,则升高权重。
小结与讨论
本小节主要介绍了神经网络的训练的训练流程,损失函数,梯度下降和反向传播。
请读者思考,反向传播过程是否有好办法通过工具自动化求解?
参考文献
《智能之门》,胡晓武等著,高等教育出版社
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
Zeiler, M. D. (2012). ADADELTA: an adaptive learning rate method. arXiv preprint arXiv:1212.5701.
Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26-31.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
周志华老师的西瓜书《机器学习》
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
Inoue H. Data Augmentation by Pairing Samples for Images Classification[J]. 2018.
Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
《深度学习》- 伊恩·古德费洛
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf