2.4-解决分类问题
本小节主要围绕解决分类问题中的提出问题,定义神经网络结构,前向计算,反向传播展开介绍。
2.4.1 提出问题
我们有如表 2.4.1 所示的1000个样本和标签。
表 2.4.1 多分类问题数据样本
| 样本 | |||
|---|---|---|---|
| 1 | 0.22825111 | -0.34587097 | 2 |
| 2 | 0.20982606 | 0.43388447 | 3 |
| ... | ... | ... | ... |
| 1000 | 0.38230143 | -0.16455377 | 2 |
还好这个数据只有两个特征,所以我们可以用可视化的方法展示,如图 2.4.1。
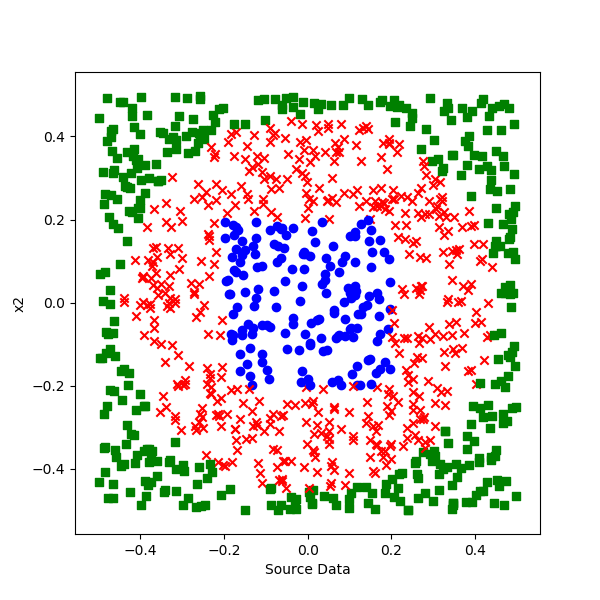
图 2.4.1 可视化样本数据
一共有3个类别:
- 蓝色方点
- 红色叉点
- 绿色圆点
样本组成了一个貌似铜钱的形状,我们就把这个问题叫做“铜钱孔形分类”问题吧。
三种颜色的点有规律地占据了一个单位平面内的不同区域,从图中可以明显看出,这不是线性可分问题,而单层神经网络只能做线性分类,如果想做非线性分类,需要至少两层神经网络来完成。
红绿两色是圆形边界分割,红蓝两色是个矩形边界,都是有规律的。但是,学习神经网络,要忘记“规律”这个词,对于神经网络来说,数学上的“有规律”或者“无规律”是没有意义的,对于它来说一概都是无规律,训练难度是一模一样的。
另外,边界也是无意义的,要用概率来理解:没有一条非0即1的分界线来告诉我们哪些点应该属于哪个区域,我们可以得到的是处于某个位置的点属于三个类别的概率有多大,然后我们从中取概率最大的那个类别作为最终判断结果。
2.4.2 定义神经网络结构
先设计出能完成非线性多分类的网络结构,如图11-2所示。
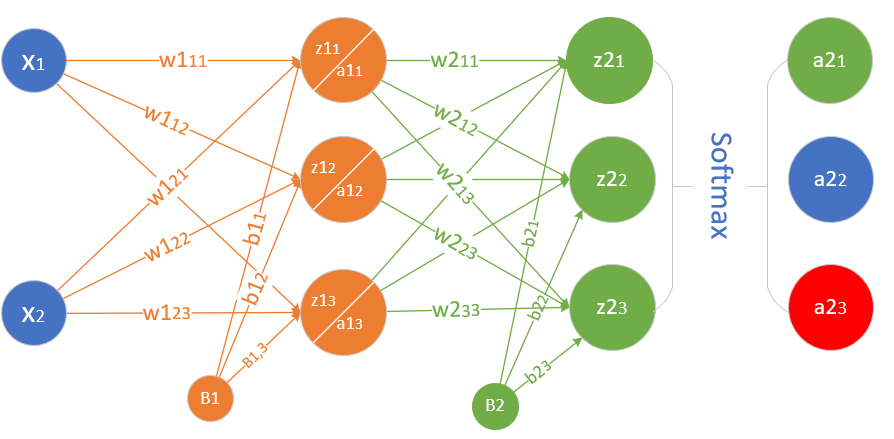
图 2.4.2 非线性多分类的神经网络结构图
- 输入层两个特征值
- 隐层的权重矩阵
- 隐层的偏移矩阵
- 隐层由3个神经元构成
- 输出层的权重矩阵
- 输出层的偏移矩阵
- 输出层有3个神经元使用Softmax函数进行分类
2.4.3 前向计算
根据网络结构,可以绘制前向计算图,如图 2.4.3 所示。
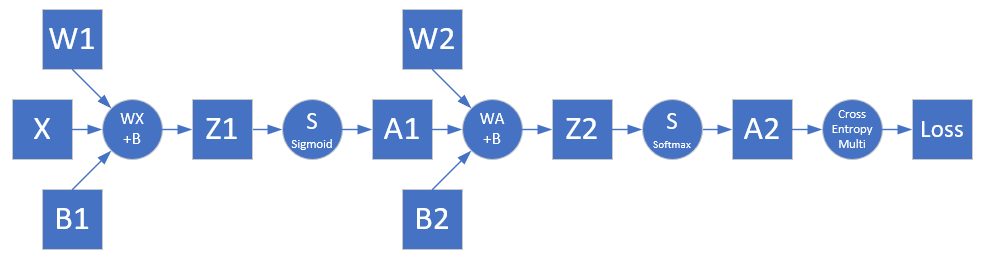
图 2.4.3 前向计算图
第一层
- 线性计算
- 激活函数
第二层
- 线性计算
- 分类函数
损失函数
使用多分类交叉熵损失函数:
loss = -(y_1 \ln a2_1 + y_2 \ln a2_2 + y_3 \ln a2_3) \\ J(w,b) = -\frac{1}{m} \sum^m_{i=1} \sum^n_{j=1} y_{ij} \ln (a2_{ij})为样本数,为类别数。
2.4.4 反向传播
根据前向计算图,可以绘制出反向传播的路径如图 2.4.4。
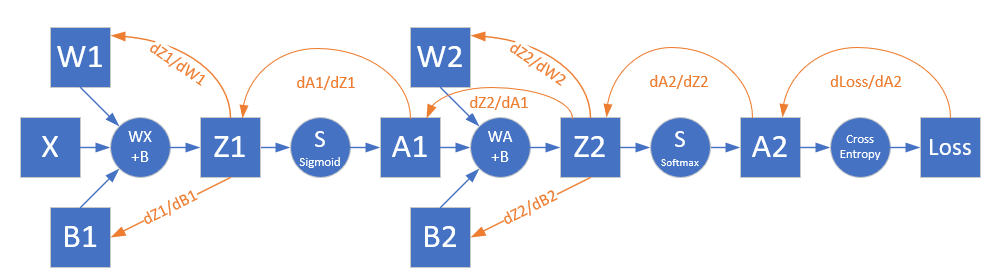
图 2.4.4 反向传播图
Softmax与多分类交叉熵配合时的反向传播推导过程,最后是一个很简单的减法:
从Z2开始再向前推:
2.4.5 运行结果
训练过程如图 2.4.5 所示。
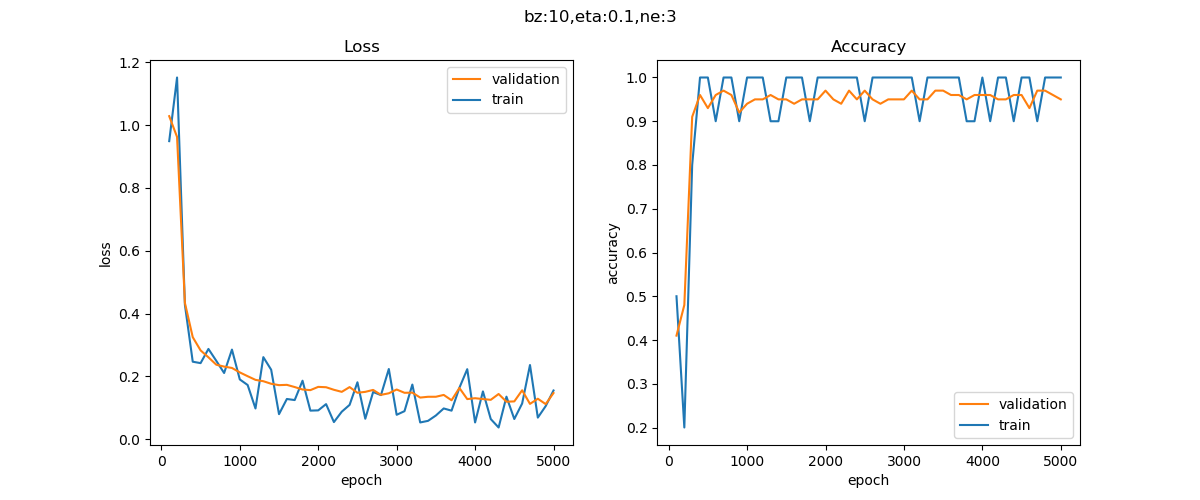
图 2.4.5 训练过程中的损失函数值和准确率值的变化
迭代了5000次,没有到达损失函数小于0.1的条件。
分类结果如图 2.4.6 所示。
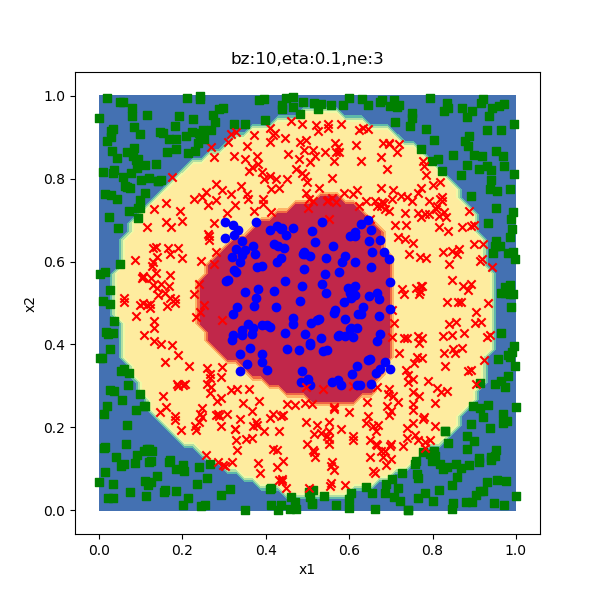
图 2.4.6 分类效果图
因为没达到精度要求,所以分类效果一般。从分类结果图上看,外圈圆形差不多拟合住了,但是内圈的方形还差很多,最后的测试分类准确率为0.952。如果在第一层增加神经元的数量(目前是 3,可以尝试 8),是可以得到比较满意的结果的。
小结与讨论
本小节主要介绍了解决分类问题中的提出问题,定义神经网络结构,前向计算,反向传播。
请读者通过PyTorch实现一个模型解决一个简单的分类问题。
参考文献
《智能之门》,胡晓武等著,高等教育出版社
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
Zeiler, M. D. (2012). ADADELTA: an adaptive learning rate method. arXiv preprint arXiv:1212.5701.
Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26-31.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
周志华老师的西瓜书《机器学习》
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
Inoue H. Data Augmentation by Pairing Samples for Images Classification[J]. 2018.
Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
《深度学习》- 伊恩·古德费洛
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf