2.5-深度神经网络
本小节主要围绕,深度神经网络,权重矩阵初始化,批量归一化,过拟合内容进行介绍。
2.5.1 抽象与设计
比较神经网络的基础代码,我们可以看到大量的重复之处,比如前向计算中,都是:矩阵运算+激活/分类函数。再看看反向传播:每一层的模式也非常相近:计算本层的dZ,再根据dZ计算dW和dB。
因为三层网络比两层网络多了一层,所以会在初始化、前向、反向、更新参数等四个环节有所不同,但却是有规律的。再加上前面章节中,为了实现一些辅助功能,我们已经写了很多类。所以,现在可以动手搭建一个深度学习的迷你框架了。
图 2.5.1 是迷你框架的模块化设计,下面对各个模块做功能点上的解释。
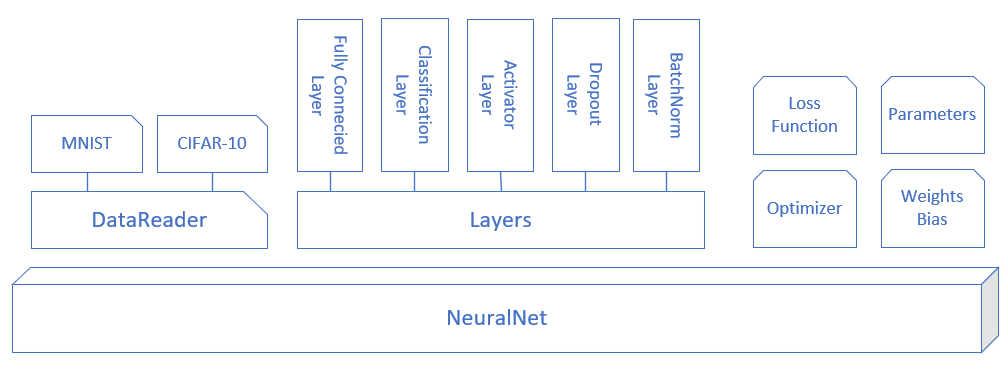
图 2.5.1 迷你框架设计
- NeuralNet:首先需要一个
NeuralNet类,来包装基本的神经网络结构和功能 - Layer:是一个抽象类,以及更加需要增加的实际类
- Activator Layer:激活函数和分类函数
- Classification Layer:分类函数,包括
Sigmoid二分类,Softmax多分类 - Parameters:基本神经网络运行参数
- LossFunction:损失函数及帮助方法
- Optimizer:优化器
- WeightsBias:权重矩阵,仅供全连接层使用
- DataReader:样本数据读取器
2.5.2 权重矩阵初始化
权重矩阵初始化是一个非常重要的环节,是训练神经网络的第一步,选择正确的初始化方法会带了事半功倍的效果。这就好比攀登喜马拉雅山,如果选择从南坡登山,会比从北坡容易很多。而初始化权重矩阵,相当于下山时选择不同的道路,在选择之前并不知道这条路的难易程度,只是知道它可以抵达山下。这种选择是随机的,即使你使用了正确的初始化算法,每次重新初始化时也会给训练结果带来很多影响。
比如第一次初始化时得到权重值为(0.12847,0.36453),而第二次初始化得到(0.23334,0.24352),经过试验,第一次初始化用了3000次迭代达到精度为96%的模型,第二次初始化只用了2000次迭代就达到了相同精度。这种情况在实践中是常见的。
常用的初始化方法有以下几种。
零初始化
即把所有层的W值的初始值都设置为0。
但是对于多层网络来说,绝对不能用零初始化,否则权重值不能学习到合理的结果。。
标准初始化
标准正态初始化方法保证激活函数的输入均值为0,方差为1。将W按如下公式进行初始化:
其中的W为权重矩阵,N表示高斯分布,Gaussian Distribution,也叫做正态分布,Normal Distribution,所以有的地方也称这种初始化为Normal初始化。
一般会根据全连接层的输入和输出数量来决定初始化的细节:
Xavier初始化方法
条件:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
其中的W为权重矩阵,N表示正态分布(Normal Distribution),U表示均匀分布(Uniform Distribution)。下同。
假设激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign。
即权重矩阵参数应该满足在该区间内的均匀分布。其中的W是权重矩阵,U是Uniform分布,即均匀分布。
MSRA初始化方法
条件:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
“Xavier”是一种相对不错的初始化方法,但是,Xavier推导的时候假设激活函数在零点附近是线性的,显然我们目前常用的ReLU和PReLU并不满足这一条件。所以MSRA初始化主要是想解决使用ReLU激活函数后,方差会发生变化,因此初始化权重的方法也应该变化。
只考虑输入个数时,MSRA初始化是一个均值为0,方差为2/n的高斯分布,适合于ReLU激活函数:
2.5.3 批量归一化
既然可以把原始训练样本做归一化,那么如果在深度神经网络的每一层,都可以有类似的手段,也就是说把层之间传递的数据移到0点附近,那么训练效果就应该会很理想。这就是批归一化BN的想法的来源。
深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢,这是个在DL领域很接近本质的问题。很多论文都是解决这个问题的,比如ReLU激活函数,再比如Residual Network。BN本质上也是解释并从某个不同的角度来解决这个问题的。
BN就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同的分布,致力于将每一层的输入数据正则化成的分布。因次,每次训练的数据必须是mini-batch形式,一般取32,64等数值。
具体的数据处理过程如图 2.5.2 所示。
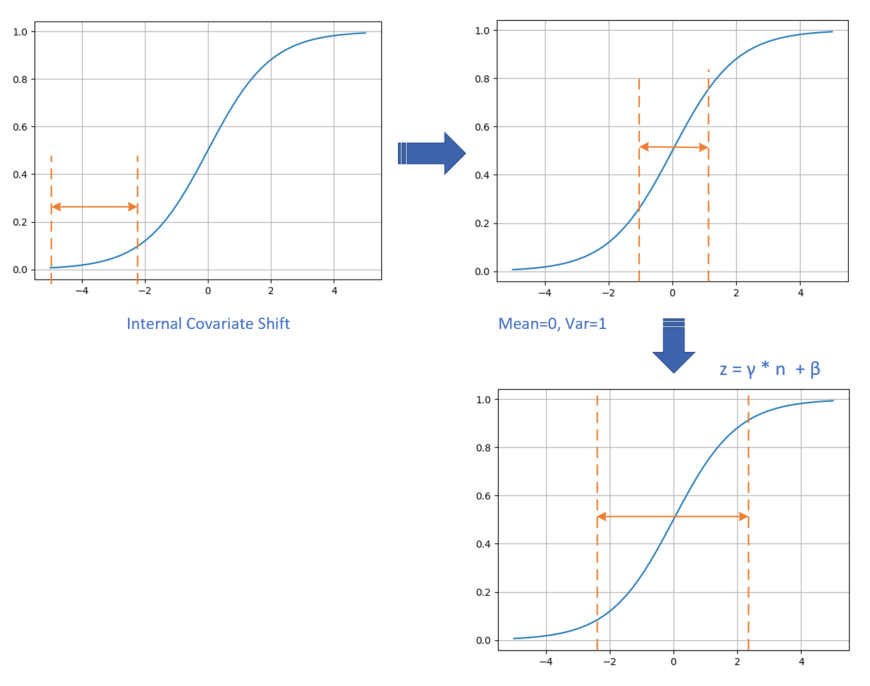
图 2.5.2 数据处理过程
数据在训练过程中,在网络的某一层会发生Internal Covariate Shift,导致数据处于激活函数的饱和区;
经过均值为0、方差为1的变换后,位移到了0点附近。但是只做到这一步的话,会带来两个问题:
a. 在[-1,1]这个区域,Sigmoid激活函数是近似线性的,造成激活函数失去非线性的作用;
b. 在二分类问题中我们学习过,神经网络把正类样本点推向了右侧,把负类样本点推向了左侧,如果再把它们强行向中间集中的话,那么前面学习到的成果就会被破坏;
经过的线性变换后,把数据区域拉宽,则激活函数的输出既有线性的部分,也有非线性的部分,这就解决了问题a;而且由于也是通过网络进行学习的,所以以前学到的成果也会保持,这就解决了问题b。
在实际的工程中,我们把BN当作一个层来看待,一般架设在全连接层(或卷积层)与激活函数层之间。
前向计算
表 2.5.1 中,m表示batch_size的大小,比如32或64个样本/批;n表示features数量,即样本特征值数量。
表 2.5.1 各个参数的含义和数据形状
| 符号 | 数据类型 | 数据形状 |
|---|---|---|
| 输入数据矩阵 | [m, n] | |
| 输入数据第i个样本 | [1, n] | |
| 经过归一化的数据矩阵 | [m, n] | |
| 经过归一化的单样本 | [1, n] | |
| 批数据均值 | [1, n] | |
| 批数据方差 | [1, n] | |
| 批样本数量 | [1] | |
| 线性变换参数 | [1, n] | |
| 线性变换参数 | [1, n] | |
| 线性变换后的矩阵 | [1, n] | |
| 线性变换后的单样本 | [1, n] | |
| 反向传入的误差 | [m, n] |
如无特殊说明,以下乘法为元素乘,即element wise的乘法。
在训练过程中,针对每一个batch数据,m是批的大小。进行的操作是,将这组数据正则化,之后对其进行线性变换。
具体的算法步骤是:
其中,是训练出来的,是防止为0时加的一个很小的数值,通常为1e-5。
批量归一化的优点
可以选择比较大的初始学习率,让你的训练速度提高。
以前还需要慢慢调整学习率,甚至在网络训练到一定程度时,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性;
减少对初始化的依赖
一个不太幸运的初始化,可能会造成网络训练实际很长,甚至不收敛。
减少对正则的依赖
在第16章中,我们将会学习正则化知识,以增强网络的泛化能力。采用BN算法后,我们会逐步减少对正则的依赖,比如令人头疼的dropout、L2正则项参数的选择问题,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性;
2.5.4 过拟合
拟合程度比较
在深度神经网络中,我们遇到的另外一个挑战,就是网络的泛化问题。所谓泛化,就是模型在测试集上的表现要和训练集上一样好。经常有这样的例子:一个模型在训练集上千锤百炼,能到达99%的准确率,拿到测试集上一试,准确率还不到90%。这说明模型过度拟合了训练数据,而不能反映真实世界的情况。解决过度拟合的手段和过程,就叫做泛化。
神经网络的两大功能:回归和分类。这两类任务,都会出现欠拟合和过拟合现象,如图16-1和16-2所示。
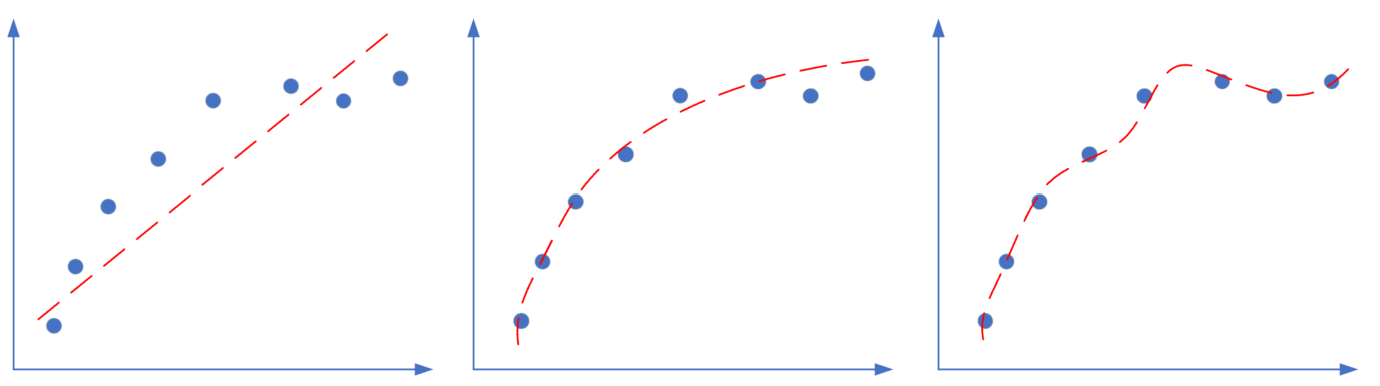
图 2.5.3 回归任务中的欠拟合、正确的拟合、过拟合
图 2.5.3 是回归任务中的三种情况,依次为:欠拟合、正确的拟合、过拟合。
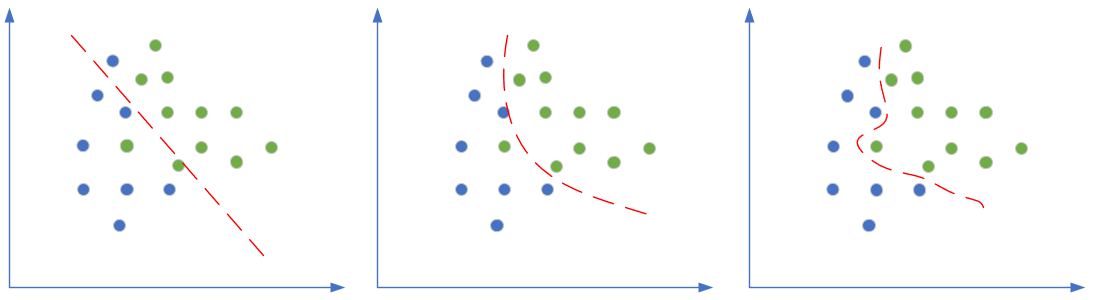
图 2.5.4 分类任务中的欠拟合、正确的拟合、过拟合
图 2.5.4 是分类任务中的三种情况,依次为:分类欠妥、正确的分类、分类过度。由于分类可以看作是对分类边界的拟合,所以我们经常也统称其为拟合。
上图中对于“深入敌后”的那颗绿色点样本,正确的做法是把它当作噪音看待,而不要让它对网络产生影响。而对于上例中的欠拟合情况,如果简单的(线性)模型不能很好地完成任务,我们可以考虑使用复杂的(非线性或深度)模型,即加深网络的宽度和深度,提高神经网络的能力。
但是如果网络过于宽和深,就会出现第三张图展示的过拟合的情况。
出现过拟合的原因
- 训练集的数量和模型的复杂度不匹配,样本数量级小于模型的参数
- 训练集和测试集的特征分布不一致
- 样本噪音大,使得神经网络学习到了噪音,正常样本的行为被抑制
- 迭代次数过多,过分拟合了训练数据,包括噪音部分和一些非重要特征
既然模型过于复杂,那么我们简化模型不就行了吗?为什么要用复杂度不匹配的模型呢?有两个原因:
- 因为有的模型以及非常成熟了,比如VGG16,可以不调参而直接用于你自己的数据训练,此时如果你的数据数量不够多,但是又想使用现有模型,就需要给模型加正则项了。
- 使用相对复杂的模型,可以比较快速地使得网络训练收敛,以节省时间。
最终我们可以得到如图 2.5.5 所示的训练曲线。
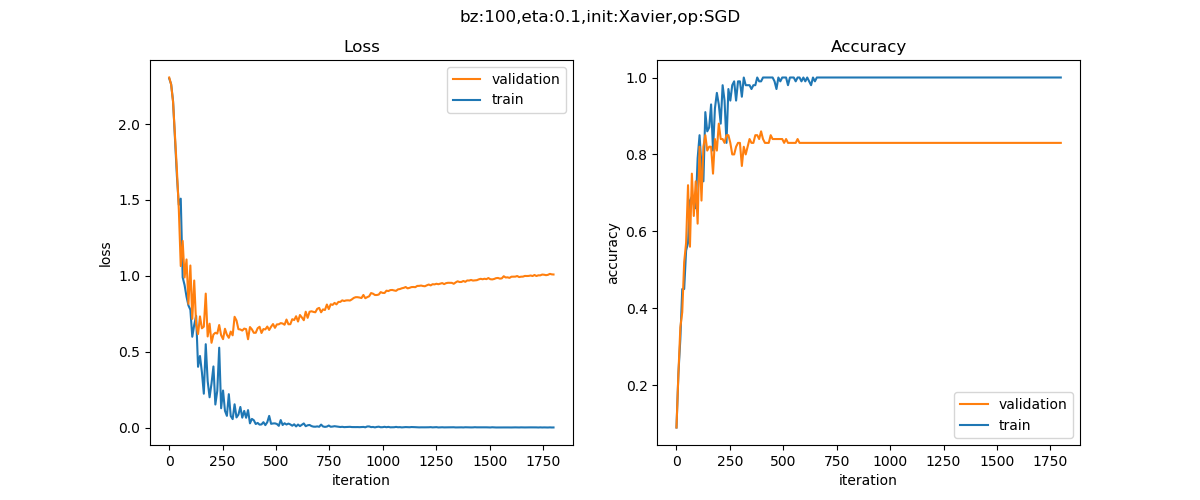
图 2.5.5 过拟合例子二的训练曲线
在训练集上(蓝色曲线),很快就达到了损失函数值趋近于0,准确度100%的程度。而在验证集上(红色曲线),损失函数值却越来越大,准确度也在下降。这就造成了一个典型的过拟合网络,即所谓U型曲线,无论是损失函数值和准确度,都呈现出了这种分化的特征。
解决方案
有了直观感受和理论知识,下面我们看看如何解决过拟合问题:
- 数据扩展(Data Augmentation)
- L2 / L1 正则 (Regularization)
- 丢弃法 (Dropout)
- 早停法 (Early Stop)
- 集成学习法 (Ensemble Learning)
- 特征工程(属于传统机器学习范畴,不在此处讨论)
- 简化模型,减小网络的宽度和深度
篇幅有限不再展开,有兴趣的读者请参考《智能之门》一书。
小结与讨论
本小节主要介绍了深度神经网络,权重矩阵初始化,批量归一化,过拟合内容。
请读者尝试通过以上方法调优已有的一个模型训练过程,观察模型的收敛性。并思考能否自动化调优当前的一些配置?
参考文献
《智能之门》,胡晓武等著,高等教育出版社
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
Zeiler, M. D. (2012). ADADELTA: an adaptive learning rate method. arXiv preprint arXiv:1212.5701.
Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26-31.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
周志华老师的西瓜书《机器学习》
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
Inoue H. Data Augmentation by Pairing Samples for Images Classification[J]. 2018.
Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
《深度学习》- 伊恩·古德费洛
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf