2.8-循环神经网络
本小节主要围绕循环神经网络,循环神经网络的发展简史,循环神经网络的结构和典型用途,深度循环神经网络,双向循环神经网络,高级循环神经网络展开介绍。
2.8.1 循环神经网络的发展简史
循环神经网络(RNN,Recurrent Neural Network)的历史可以简单概括如下:
- 1933年,西班牙神经生物学家Rafael Lorente de Nó发现大脑皮层(cerebral cortex)的解剖结构允许刺激在神经回路中循环传递,并由此提出反响回路假设(reverberating circuit hypothesis)。
- 1982年,美国学者John Hopfield使用二元节点建立了具有结合存储(content-addressable memory)能力的神经网络,即Hopfield神经网络。
- 1986年,Michael I. Jordan基于Hopfield网络的结合存储概念,在分布式并行处理(parallel distributed processing)理论下建立了新的循环神经网络,即Jordan网络。
- 1990年,Jeffrey Elman提出了第一个全连接的循环神经网络,Elman网络。Jordan网络和Elman网络是最早出现的面向序列数据的循环神经网络,由于二者都从单层前馈神经网络出发构建递归连接,因此也被称为简单循环网络(Simple Recurrent Network, SRN)。
- 1990年,Paul Werbos提出了循环神经网络的随时间反向传播(BP Through Time,BPTT),BPTT被沿用至今,是循环神经网络进行学习的主要方法。
- 1991年,Sepp Hochreiter发现了循环神经网络的长期依赖问题(long-term dependencies problem),大量优化理论得到引入并衍生出许多改进算法,包括神经历史压缩器(Neural History Compressor, NHC)、长短期记忆网络(Long Short-Term Memory networks, LSTM)、门控循环单元网络(Gated Recurrent Unit networks, GRU)、回声状态网络(echo state network)、独立循环神经网络(Independent RNN)等。
图 2.8.1 简单描述了从前馈神经网络到循环神经网络的演化过程。
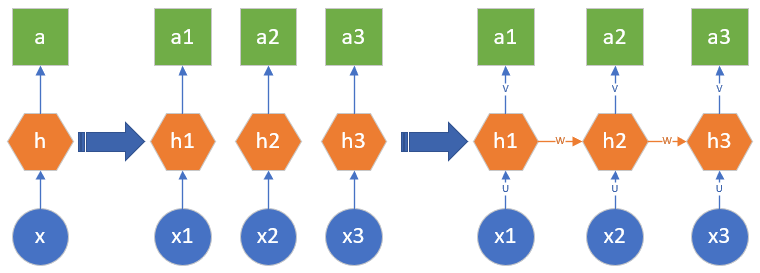
图 2.8.1 从前馈神经网络到循环神经网络的演化
- 最左侧的是前馈神经网络的概括图,即,根据一个静态的输入数据x,经过隐层h的计算,最终得到结果a。这里的h是全连接神经网络或者卷积神经网络,a是回归或分类的结果。
- 当遇到序列数据的问题后(假设时间步数为3),可以建立三个前馈神经网络来分别处理t=1、t=2、t=3的数据,即x1、x2、x3
- 但是两个时间步之间是有联系的,于是在隐层h1、h2、h3之间建立了一条连接线,实际上是一个矩阵W
- 根据序列数据的特性,可以扩充时间步的数量,在每个相邻的时间步之间都会有联系
如果仅此而已的话,还不能称之为循环神经网络,只能说是多个前馈神经网络的堆叠而已。在循环神经网络中,以图19-1最右侧的图为例,只有三个参数:
- U:是x到隐层h的权重矩阵
- V:是隐层h到输出a的权重矩阵
- W:是相邻隐层h之间的权重矩阵
请注意这三个参数在不同的时间步是共享的,以图19-1最右侧的图为例,三个U其实是同一个矩阵,三个V是同一个矩阵,两个W是同一个矩阵。这样的话,无论有多少个时间步,都可以像折扇一样“折叠”起来,用一个“循环”来计算各个时间步的输出,这才是“循环神经网络”的真正含义。
2.8.2 循环神经网络的结构和典型用途
一对多的结构
在国外,用户可以指定一个风格,或者一段旋律,让机器自动生成一段具有巴赫风格的乐曲。在中国,有藏头诗的娱乐形式,比如以“春”字开头的一句五言绝句可以是“春眠不觉晓”、“春草细还生”等等。这两个例子都是只给出一个输入,生成多个输出的情况,如图 2.8.2 所示。
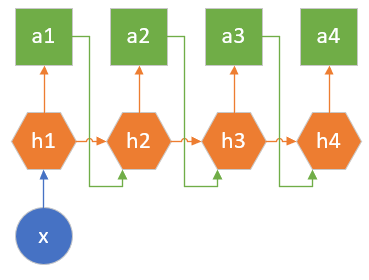
图 2.8.2 一对多的结构示意图
这种情况的特殊性在于,第一个时间步生成的结果要做为第二个时间步的输入,使得前后有连贯性。图中只画出了4个时间步,在实际的应用中,如果是五言绝句,则有5个时间步;如果是音乐,则要指定小节数,比如40个小节,则时间步为40。
多对一的结构
在阅读一段影评后,会判断出该观众对所评价的电影的基本印象如何,比如是积极的评价还是消极的评价,反映在数值上就是给5颗星还是只给1颗星。在这个例子中,输入是一段话,可以拆成很多句或者很多词组,输出则是一个分类结果。这是一个多个输入单个输出的形式,如图 2.8.3 所示。
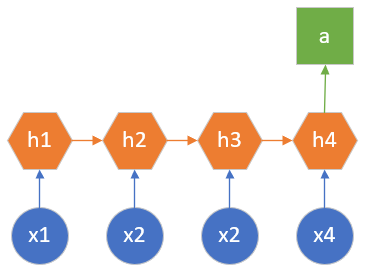
图 2.8.3 多对一的示意图
图中x可以看作很多连续的词组,依次输入到网络中,只在最后一个时间步才有一个统一的输出。另外一种典型的应用就是视频动作识别,输入连续的视频帧(图片形式),输出是分类结果,比如“跑步”、“骑车”等等动作。
还有一个很吸引人的应用就是股票价格的预测,输入是前10天的股票基本数据,如每天的开盘价、收盘价、交易量等,而输出是明天的股票的收盘价,这也是典型的多对一的应用。但是由于很多其它因素的干扰,股票价格预测具有很大的不确定性。
多对多(输入输出等量)
这种结构要求输入的数据时间步的数量和输出的数据的时间步的数量相同,如图 2.8.4所示。
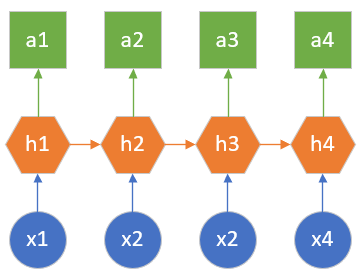
图 2.8.4 多对多结构
比如想分析视频中每一帧的分类,则输入100帧输入,输出是对应的100个分类结果。另外一个典型应用就是基于字符的语言模型,比如对于英文单词“hello”来说,当第一个字母是h时,计算第二个字母是e的概率,以此类推,则输入是“hell”四个字母,输出是“ello”四个字母的概率。
在中文中,对联的生成问题也是使用了这种结构,如果上联是“风吹水面层层浪”七个字,则下联也一定是七个字,如“雨打沙滩点点坑”。
多对多(输入输出不等量)
这是循环神经网络最重要的一个变种,又叫做编码解码(Encoder-Decoder)模型,或者序列到序列(seqence to seqence)模型,如图 2.8.5 所示。
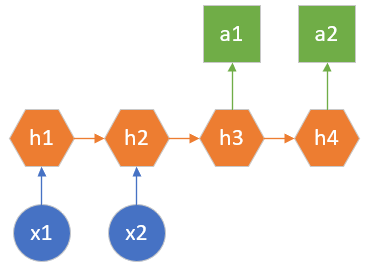
图 2.8.5 编码解码模型
以机器翻译任务举例,源语言和目标语言的句子通常不会是相同的长度,为此,此种结构会先把输入数据编码成一个上下文向量,在h2后生成,做为h3的输入。此时,h1和h2可以看做是一个编码网络,h3和h4看做是一个解码网络。解码网络拿到编码网络的输出后,进行解码,得到目标语言的句子。
由于这种结构不限制输入和输出的序列长度,所以应用范围广泛,类似的应用还有:
- 文本摘要:输入是一段文本,输出是摘要,摘要的字数要比正文少很多。
- 阅读理解:输入是文章和问题,输出是问题答案,答案一般都很简短。
- 语音识别,输入是语音信号序列,输出是文字序列,输入的语音信号按时间计算长度,而输出按字数计算长度,根本不是一个量纲。
2.8.3 深度循环神经网络
前面的几个例子中,单独看每一时刻的网络结构,其实都是由“输入层->隐层->输出层”所组成的,这与我们在前馈神经网络中学到的单隐层的知识一样,由于输入层不算做网络的一层,输出层是必须具备的,所以网络只有一个隐层。我们知道单隐层的能力是有限的,所以人们会使用更深(更多隐层)的网络来解决复杂的问题。
在循环神经网络中,会有同样的需求,要求每一时刻的网络是由多个隐层组成。比如图 2.8.6 为两个隐层的循环神经网络。
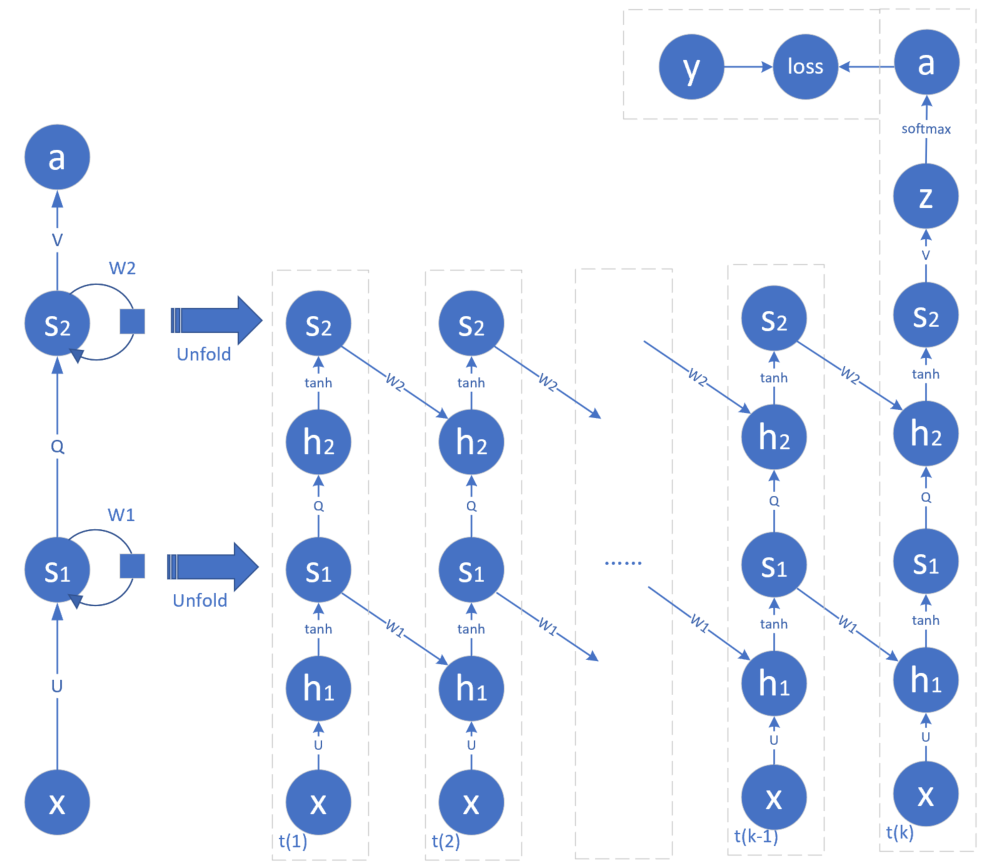
图 2.8.6 两个隐层的循环神经网络
注意最左侧的两个隐藏状态s1和s2是同时展开为右侧的图的,这样的循环神经网络称为深度循环神经网络,它可以具备比单隐层的循环神经网络更强大的能力。
2.8.4 双向循环神经网络
前面学习的内容,都是因为“过去”的时间步的状态对“未来”的时间步的状态有影响,在本节中,我们将学习一种双向影响的结构,即双向循环神经网络。
比如在一个语音识别的模型中,可能前面的一个词听上去比较模糊,会产生多个猜测,但是后面的词都很清晰,于是可以用后面的词来为前面的词提供一个最有把握(概率最大)的猜测。再比如,在手写识别应用中,前面的笔划与后面的笔划是相互影响的,特别是后面的笔划对整个字的识别有较大的影响。
在本节中会出现两组相似的词:前向计算、反向传播、正向循环、逆向循环。区别如下:
- 前向计算:是指神经网络中通常所说的前向计算,包括正向循环的前向计算和逆向循环的前向计算。
- 反向传播:是指神经网络中通常所说的反向传播,包括正向循环的反向传播和逆向循环的反向传播。
- 正向循环:是指双向循环神经网络中的从左到右时间步。在正向过程中,会存在前向计算和反向传播。
- 逆向循环:是指双向循环神经网络中的从右到左时间步。在逆向过程中,也会存在前向计算和反向传播。
双向循环神经网络图如图 2.8.7 所示。
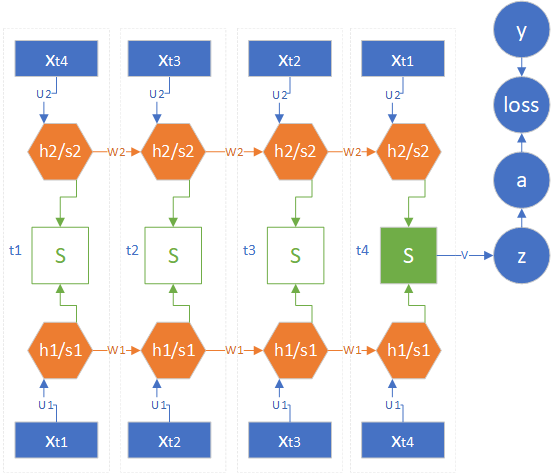
图 2.8.7 双向循环神经网络结构图
用表示正向循环的隐层状态,、表示权重矩阵;用表示逆向循环的隐层状态,、表示权重矩阵。 是 的激活函数结果。
请注意上下两组至的顺序是相反的:
- 对于正向循环的最后一个时间步来说, 作为输入,是最后一个时间步的隐层值;
- 对于逆向循环的最后一个时间步来说, 作为输入,是最后一个时间步的隐层值;
- 然后 和 拼接得到 ,再通过与权重矩阵 相乘得出 。
图 2.8.7 中的 节点有两种,一种是绿色实心的,表示有实际输出;另一种是绿色空心的,表示没有实际输出,对于没有实际输出的节点,也不需要做反向传播的计算。
2.8.5 高级循环神经网络简介
针对上述问题,科学家们对普通循环神经网络进行改进,以便处理更复杂场景的数据的模型,提出了如LSTM, GRU, Seq2Seq等模型。此外,注意力(Attention)机制的引入,使得Seq2Seq模型的性能得到提升,关于Attention的内容,目前没有列入章节,以后将会进行补充。
下面简单介绍本章将会讲解的三种网络模型。
长短时记忆网络(LSTM)
长短时记忆网络(LSTM)是最先提出的改进算法,由于门控单元的引入,从根本上解决了梯度爆炸和消失的问题,使网络可以处理长距离依赖。
门控循环单元网络(GRU)
LSTM网络结构中有三个门控单元和两个状态,参数较多,实现复杂。为此,针对LSTM提出了许多变体,其中门控循环单元网络是最流行的一种,它将三个门减少为两个,状态也只保留一个,和普通循环神经网络保持一致。
序列到序列网络(Sequence-to-Sequence)
LSTM与其变体很好地解决了网络中梯度爆炸和消失的问题。但LSTM有一个缺陷,无法处理输入和输出序列不等长的问题,为此提出了序列到序列(Sequence-to-Sequence, 简称Seq2Seq)模型,引入和编码解码机制(Encoder-Decoder),在机器翻译等领域取得了很大的成果,进一步提升了循环神经网络的处理范围。
小结与讨论
本小节主要介绍了循环神经网络,循环神经网络的发展简史,循环神经网络的结构和典型用途,深度循环神经网络,双向循环神经网络,高级循环神经网络。
请读者思考循环神经网络和卷积神经网络分别适合哪些场景?
参考文献
《智能之门》,胡晓武等著,高等教育出版社
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul), 2121-2159.
Zeiler, M. D. (2012). ADADELTA: an adaptive learning rate method. arXiv preprint arXiv:1212.5701.
Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26-31.
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
周志华老师的西瓜书《机器学习》
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1):321-357.
Inoue H. Data Augmentation by Pairing Samples for Images Classification[J]. 2018.
Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond Empirical Risk Minimization[J]. 2017.
《深度学习》- 伊恩·古德费洛
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf